KKTV - NTU Data Analytics Term Project
As a final project for my NTU datascience course we where challenged to participate in a private Kaggle competition NTU 111-2 Data Analytics Term Project | Kaggle. In this article I will go through how I approached the challenge.
# Understanding the Challenge: Predicting Drama-Watching Schedules
The challenge centered around the task of predicting when users would watch dramas in the upcoming week. The key to success lay in analyzing users past viewing schedules and extracting meaningful patterns and insights that could generalize to future behavior.
The data was supplied by KKTV Taiwan ([insert discription of KKTV]) with the following goals for the predictive model:
- Timely Recommendations: By accurately predicting users drama-watching habits, KKTV aimed to offer personalized recommendations to users who were likely to have free time in the upcoming week. This could enhance user engagement and satisfaction.
- Optimizing Push Notifications: Another crucial aspect was the effective scheduling of push notifications. By aligning push messages with users’ anticipated viewing times, KKTV aimed to minimize intrusive interruptions and maintain a seamless user experience.
More information can be found on the Kaggle page for the challenge: NTU 111-2 Data Analytics Term Project | Kaggle
# The data
The objective of the challenge was to predict in which timeslots the users will be active on KKTV within a week. Where each day is divided into four timeslots: 1h00, 9h00, 17h00, and 21h00, resulting in a total of 28 (4X7) timeslots to be predicted.
The data was provided in two versions: complete and light. The complete version containing the raw data from KKTV, while the light version already had been pre-processed into a simplified format (binary data of the user activity).
Since the preprocessed data lacks a lot of the features from the complete version, I decided to focus on the raw data and only using the light data as a benchmark. So for the rest of the article I will only be using the complete data set.
# complete data features
Below follows a description of the features available in the complete data set.
| |
# Measurement criteria
The measure of this competition is AUC, one is recommended here Articles introducing AUC,As easy to understand and very vivid.
# Feature engineering
I experimented with a lot of different approaches to this challenge and data exploration and cleaning was pretty straight forward, when it comes to the feature engineering I decided on two approaches. The first one being time based and the second being content based.
# Approach 1: Time based features
For the time based features I focused only on the time, for each event in the event data. The reasoning behind this is that a user is likely to have time related behavior pattern when it comes to viewing activity ex. view shows during the same timeslot on Mondays.
In actually I tried 3 slightly different approaches to the time based feature:
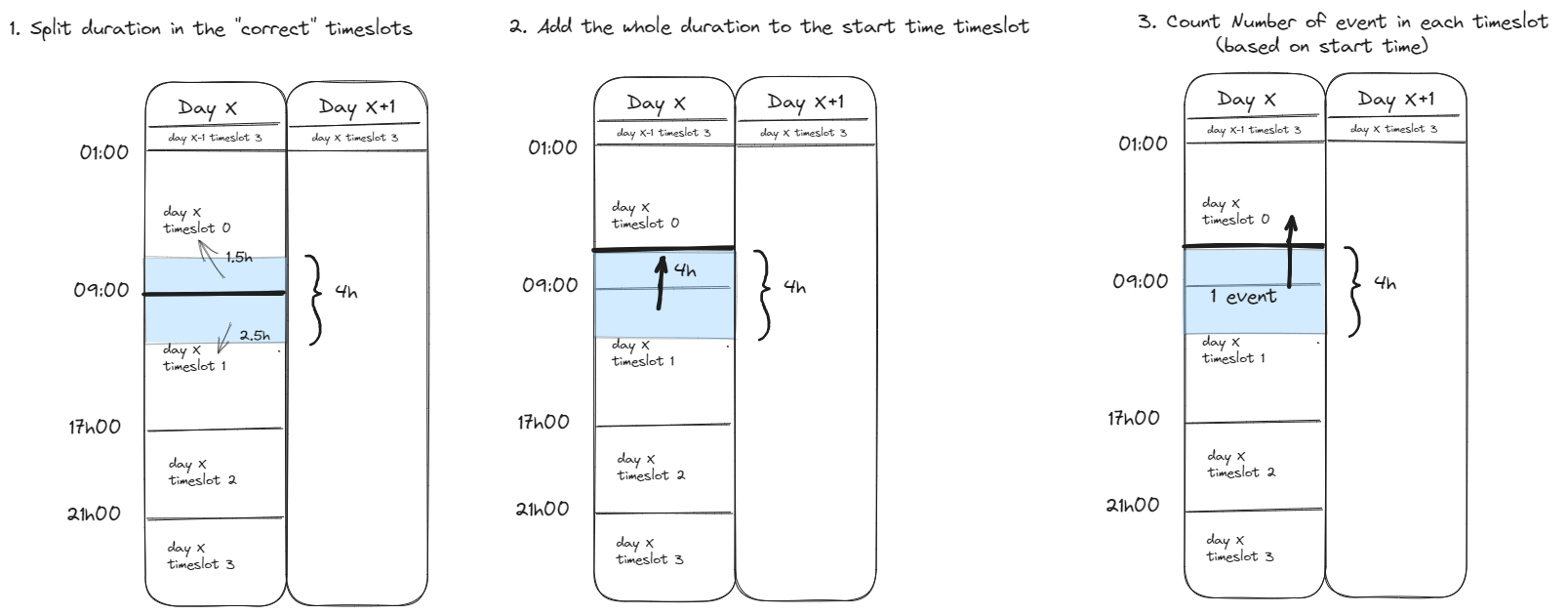
- Split duration in the “correct” timeslots This approach means we split the duration of each event based on the time slot cut of times, so that for example if we have a 4h event that starts in timeslot 0 and ends in timeslot 1, then the time in timeslot 0 will be added to timeslot 0, and the remaining time will be added to the next timeslot.
pros
- More accurate when it comes to the amount of time each user is active in a given timeslot
cons
- doesn’t take into consideration how many “events” there are in the different timeslots (i.e. if a user has multiple events throughout the time slot, it will just sum up the active time)
- more complicated to implement
- Add the whole duration to the start time timeslot Calculate the start time of the event and add the whole duration to that timeslot.
pros
- simpler than 1
cons
- doesn’t show the time spent active in each timeslot accurately, ex. if a user starts a 4h session 1min before timeslot x ends, the whole duration will be added to timeslot x, despite most of the duration actually being spent in the next timeslot.
- also doesn’t take into consideration how many “events” there are in the different timeslots.
- Number of event in each timeslot Calculate the star time for each event and use that to calculate the number of events in a given timeslot.
pros
- simple to implement
- takes into consideration nr of events
- more closely models the label data (since the thing we wanna predict is wheter a user is active during a certain timeslot not how much time they spend active)
cons
- Doesn’t take into consideration duration (an event that is 1min is counted the same as one that’s 6h) (maybe possible to improve on this by also considering duration?)
(Among these three approaches, the most effective one was the third approach, which considers the number of events in each timeslot. This may be attributed to the fact that the prediction task primarily revolves around whether there is any activity during a given timeslot rather than the exact amount of time spent. By leveraging the count of events, this approach provides a simplified yet meaningful representation of user engagement during specific time intervals.)
# Approach 2: Content based features
For approach 2 the goal was to extract features based on the content. taking into consideration the popularity of different shows, similarity in watching habits across users, generating embeddings for dramas based on their shared viewership patterns etc.
In short the following steps where followed:
- Drama Popularity Metrics Calculation:
- Total views, unique users, and average completion ratio for each drama are calculated from the training data.
- Drama Connections Filtering Based on Shared Users:
- The median number of shared users among dramas is used as a threshold.
- Drama connections are established based on shared users.
- Drama pairs with shared users meeting or exceeding the threshold are retained.
- Drama Embeddings with DeepWalk Algorithm:
- The filtered drama pairs are used to construct a graph.
- The DeepWalk algorithm, implemented using Node2Vec, generates low-dimensional embeddings for dramas based on their shared viewership patterns.
- Drama embeddings capture the underlying relationships for downstream tasks.
- User-Level Feature Extraction:
- User-level features like total played duration, total views, and unique dramas watched are aggregated from the training data.
- Merging Features and Data:
- User and drama features are merged with the original training data using relevant identifiers.
- Merging Drama Embeddings:
- Drama embeddings are merged with the training data based on drama identifiers.
- Data Formatting:
- The final dataset is organized with one row per user, containing user-level features and associated drama features.
A more detailed overview of the steps taken (as well as the code used) to generate all of the different features can be found here: GitHub - Alexnder77/-IE5054-: Some of my code for the NTU course 資料分析方法 (IE5054)
# Models
When it comes to my approach to trying out different models, tuning them and evaluating their performance, in essence the following steps where taken for both features:
- Selecting the features to use
- Separating the train data into train and validation set (using a 70-30 split)
- Training and evaluating the base-model (compare against benchmark)
- if the model did well, continue to hyperparameter tuning, trying to improve the score.
- if the score gets high enough use it to make predictions on the test data
# Benchmark
To establish a good benchmark test the light data was used with a XGB model, after tweaking the model parameters a little succeeded in reaching an AUC score of 0.80833. This benchmark was later used to evaluate the performance of my other models with the custom features.
(Note: After the completion of the challenge, when the teams where presenting our work in class the wining team (Ying Train Yi Fa NTU 111-2 Data Analytics Term Project | Kaggle) succeeded in getting a score of 0.83957 just from the light data using XGB and the right hyperparameters)
# CNN
Score: 0.82589
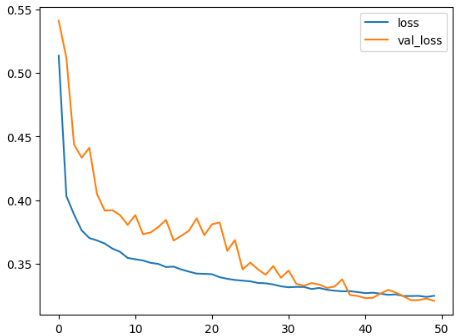
The Convolutional Neural Network (CNN) model is a deep learning architecture particularly effective in processing grid-like data, such as images or sequences. For the time-based features, the data was reshaped to take advantage of this to represent each user’s engagement across different time slots as a sequence.
The model consists of multiple convolutional and pooling layers, which can learn relevant patterns from the sequential data. These patterns can capture user behaviors like peak engagement times during certain days or time intervals. The final dense layers with a sigmoid activation function output probabilities of user activity during each time slot. By training this model on your time-based feature data, it can learn to recognize temporal patterns in users’ viewing schedules and predict their engagement in different time slots.
| |
| |
# CNN + LSTM
Score: 0.82664
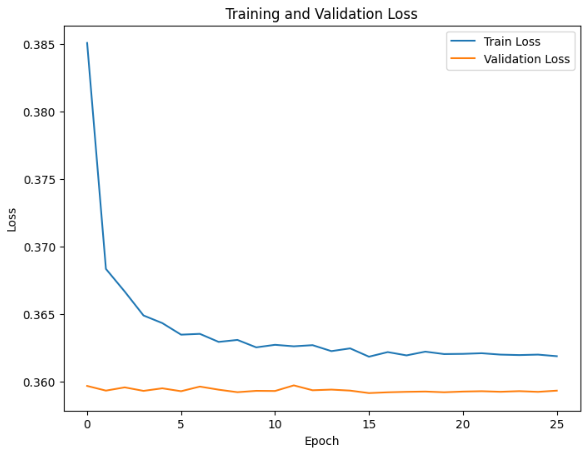
This model was used to try to combine the advantages of CNN and LSTM (Long Short-Term Memory). Which should be especially suited for modeling sequential data with spatial patterns
The CNN layers extract local patterns from the sequence, while the LSTM layers capture longer-term dependencies.
| |
# XGB
SCORE 0.83112
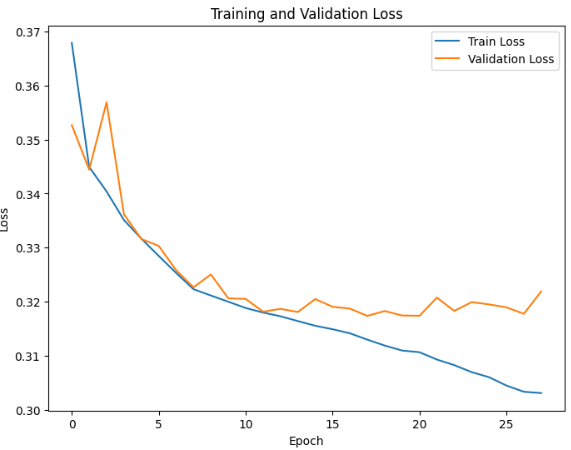
parameter values:
| |
# Ensemble learning
Two different Ensemble learning techniques was used to try to improve the score further. these techniques being weighted averaging and stacking.
# Weighted averaging
Averaging in ensemble learning refers to combining the predictions of different models by simply taking the average of the predictions. in theory this can improve the result since some models ex. LSTM might be good at predicting certain time related features where as CNN or XGB might be better at predicting other relationships. So in theory by combining the different models we can take advantage of the strengths of different models at the same time.
The simplest way to do that is through simply averaging the predictions, another usually better way is to use weighted averaging by applying a weight to the different predictions.
So if we have the above mentioned models and they generate the predictions: $P_1 , P_2 \text{ and } P_3$ we get the weighted average (WA) by applying the weights $w_1, w_2, w_3$ like this: $$WA = \frac{w_1P_1+w_2P_2+w_3P_3}{3} $$
Different weights where tried and the best combination came from combining the above 3 models with the weights: 0.4 (XGB), 0.3 (CNN) and 0.3 (CNN + LSTM) -> Score: 0.836
# Stacking
A more advanced ensemble stacking approach was also tried, based on Kaishen Tseng’s work
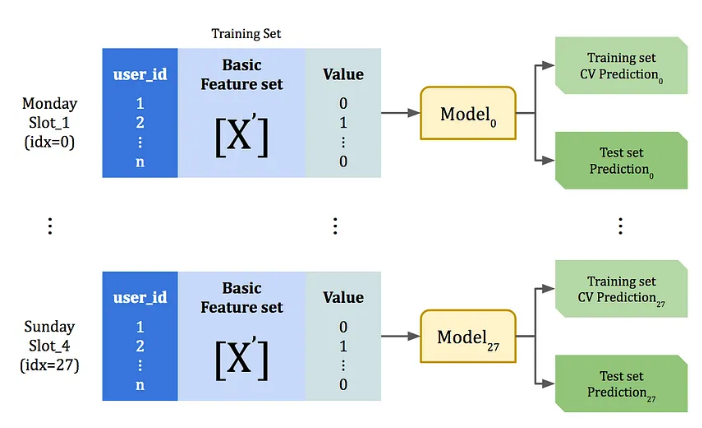 source:
KKTV Data Game-17.11 1st Place Solution | by Kaishen Tseng | Medium
source:
KKTV Data Game-17.11 1st Place Solution | by Kaishen Tseng | Medium
In short, 28 different base-models where created, one for each timeslot to be predicted. These models are trained on a subset of the train data then used to generate both train set and test set predictions.
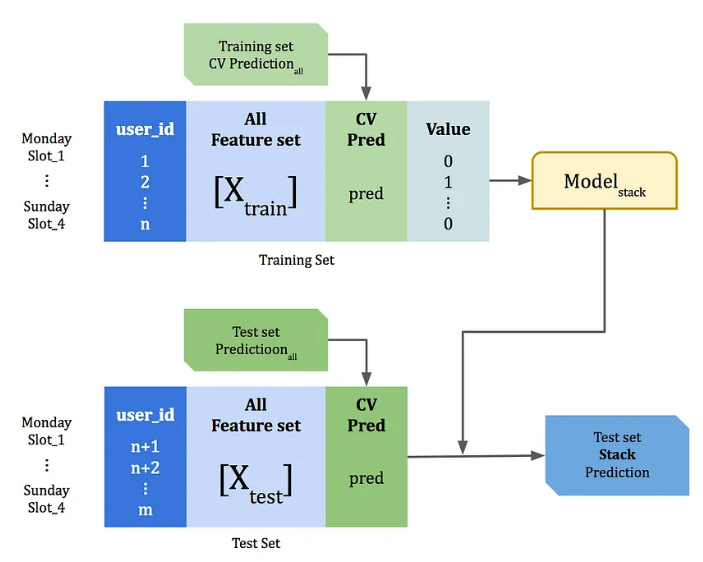 source:
KKTV Data Game-17.11 1st Place Solution | by Kaishen Tseng | Medium
source:
KKTV Data Game-17.11 1st Place Solution | by Kaishen Tseng | Medium
The train set predictions are then added to the input features (of the train set) and used to train the Stack model. This stack model is then used to make the final prediction on the test data combined with the test predictions from the previous base models.
Applying this stacking method was a lot more work than the previous methods, but for some reason the score didn’t improve.
# Discussion
This was my first Kaggle challenge and it was a lot of fun, even though my team’s leaderboard position might not have been at the top, I’m genuinely content with our achievements and the knowledge gained throughout the project.
Some Thoughts:
The Content based features didn’t score very well, its likely that there is a mistake somewhere, maybe in generating the “Drama Embeddings” since its hard to tell what these values mean once they are generated.
the team that won the challenge did so using the light data set, meaning that its possible to get a very good score using that.
Learning Opportunity: Engaging in this Kaggle competition allowed me to delve into real-world data challenges, learning valuable lessons in data preprocessing, feature engineering, and model selection.
Feature Pitfall: Although we experimented with content-based features, they didn’t yield satisfactory results. The issue might lie in the process of generating “Drama Embeddings,” which proved challenging to interpret.
Light Data Triumph: Interestingly, the winning team based their model on only the light data set (with a score of 0.83957). This underscores the fact that with clever strategies and feature utilization, good results can be achieved even with more limited data.
This also makes me wonder if a better score is achievable using my features with their model (since my features should contain more data)
In retrospect, this experience not only expanded my practical data science skills but also deepened my understanding of the iterative nature of problem-solving in a competitive setting. I’m looking forward to trying more challenges like this in the future.